sklean.datasetsのload_boston()で取り出したデータをデータフレームにするところまでのメモです。
import pandas as pd
from sklearn.datasets import load_boston
data = load_boston()
X = data["data"]
y = data["target"]
feature_names = data["feature_names"]
boston_df = pd.DataFrame(data=X, columns=feature_names)
boston_df.head()
出力はこちら。
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
このテーブルにない系列であるMEDVが現在”y”に入っている”target”の値です。
特になんの工夫もありませんが、いちいち調べるのもどうかと思うので書き置きまで。
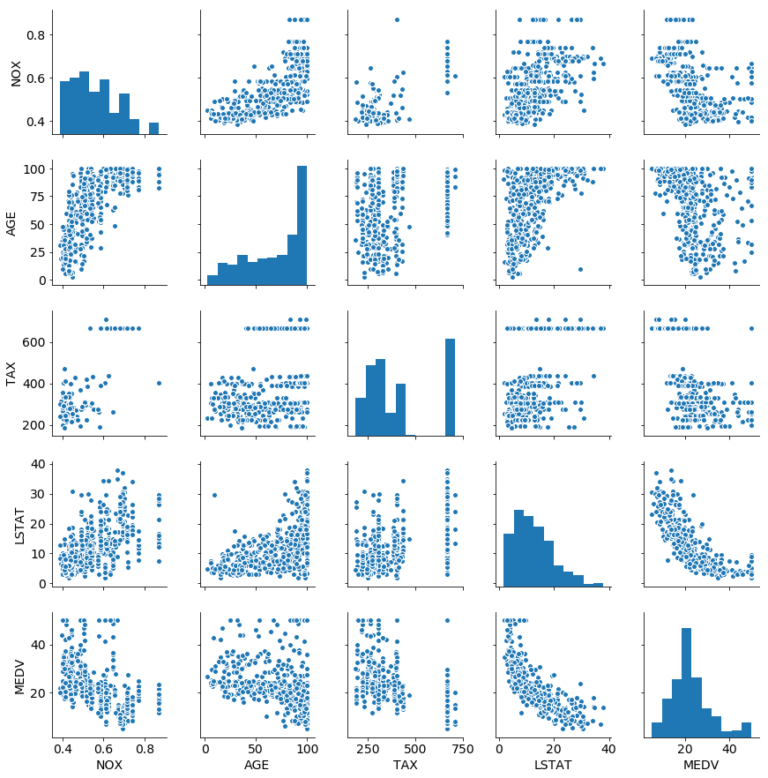
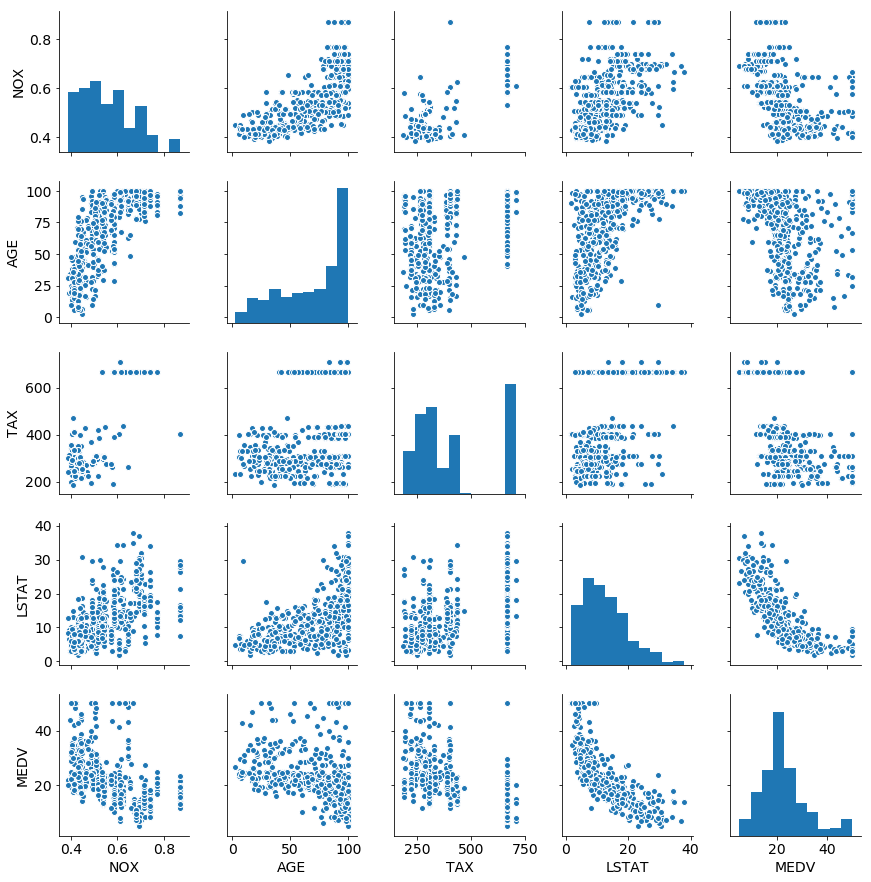
ついでに、いくつか系列をとってseabornで可視化しておきます。
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
plt.rcParams["font.size"] = 14
use_df = boston_df.copy()
use_df["MEDV"] = y
use_cols = ["NOX", "AGE", "TAX","LSTAT","MEDV"]
plt.rcParams["font.size"] = 14
sns.pairplot(data = use_df, vars=use_cols)
参考資料

Page not found · GitHub Pages
scikit-learn.org