この記事では、「体育の日に雨が降らないという印象が正しいか」という検証を行なった際に使用したコードを紹介します。
検証や考察についてはこちらの記事を参考にしてください。
本来は分析しながら考察していくのが自然な流れなのですが、結果に汎用性があったのでコードと考察を分けました。ご了承ください。
一応レベルとしては、PythonとPandasの基本を勉強して、とりあえず使ってみたい段階の人間が調べながら取り組んでいるぐらいだと想定してください。
参考になるかは分かりませんが、こんなこともできるんだな、ぐらいに思っていただければ幸いです。
事前準備
データを気象庁のページから取得しておきます。画面の一例がこちらです。
(気象庁ホームページより引用。https://www.data.jma.go.jp/gmd/risk/obsdl/index.php 2018年10月7日最終閲覧)
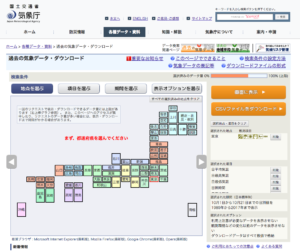
都市名や期間、必要な項目を指定し、csvファイルとしてダウンロードすればOKです。
ダウンロードの段階では何を使うか決めていなかったので色々な項目を選びましたが、今回最終的に使ったのは降雨量だけでした。
対象とする6都市それぞれについてダウンロードしたら、それぞれファイル名を”sapporo.csv”のように”都市名” + “.csv”に変更し、後でアクセスしやすいよう適当なフォルダに移動しておきます。
コードの解説
データの確認
一旦データを確認します。
ターミナル上でcatでデータを確認すると文字化けしたので、普通にファイルを開いて確認しました。
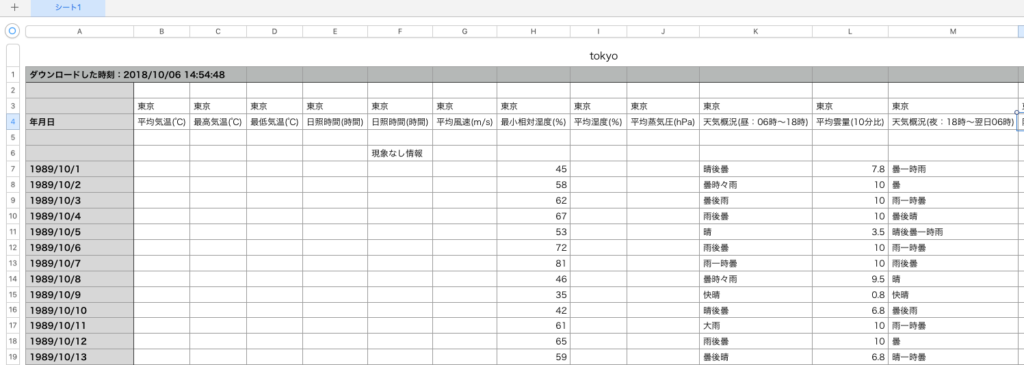
1行目にダウンロード時刻、2行目は空白行、3行目に都市情報、4行目に行の情報、5行目は空白行、6行目は行への補足情報、7行目からデータが入っているようです。
初めの6行で必要なのは4行目ですね。6行目はあとで行名を変更する際にこちらで情報を足してあげることにしました。
全体の方針
ファイルの確認をした時点で、今回の調査は降雨量に関して行なっていくことにしました。降雨量については「現象なし情報」という補足情報の行があったのですが、これを使うかどうかは実際にデータを確認してから決めることにしました。
体育の日のリストの作成
いよいよここからコードに入っていきます。初めに体育の日のリストを作成しました。
今回は標準ライブラリのcalendarのCalendarオブジェクトが持つmonthdatescalendar()を使用しました。年と月を引数で与えると、その月の日付情報をdatetime.date型でリストとして返します。
例えばこんな感じです。
# カレンダーオブジェクトを使う
import calendar
calendar_obj = calendar.Calendar()
calendar_obj.monthdatescalendar(2018, 10)[0]
[datetime.date(2018, 10, 1),
datetime.date(2018, 10, 2),
datetime.date(2018, 10, 3),
datetime.date(2018, 10, 4),
datetime.date(2018, 10, 5),
datetime.date(2018, 10, 6),
datetime.date(2018, 10, 7)]
これはリストの0番目、つまり冒頭の要素です。リストの各要素は常に月曜日から始まるので、例えば10月1日が火曜日なら、9月30日がリストに入ってくることになります。
それを踏まえて、体育の日を返す関数を作成します。冒頭で見たように、体育の日は1999年までは10月10日、2000年からは10月の第2月曜日、2020年は7月24日です。
def return_sports_day(year):
month = 10
old_sports_date_day = 10
if year == 2020:
return_date = datetime.datetime(2020, 7, 24)
elif year >= 2000:
calendar_obj = calendar.Calendar()
date_list = calendar_obj.monthdatescalendar(year, month)
if date_list[0][0].month == 10:
dateinfo = date_list[1][0]
else:
dateinfo = date_list[2][0]
return_date = datetime.datetime(dateinfo.year, dateinfo.month, dateinfo.day)
else:
return_date = datetime.datetime(year, month, old_sports_date_day)
return return_date
なお、後の処理を考えて、今回は初めからdate型ではなくdatetime型で返すようにしました。この関数を使用して、体育の日のリストを作成します。
sports_day_list = [return_sports_day(each_year) for each_year in range(1989, 2018)]
sports_day_list
[datetime.datetime(1989, 10, 10, 0, 0),
datetime.datetime(1990, 10, 10, 0, 0),
datetime.datetime(1991, 10, 10, 0, 0),
datetime.datetime(1992, 10, 10, 0, 0),
datetime.datetime(1993, 10, 10, 0, 0),
datetime.datetime(1994, 10, 10, 0, 0),
datetime.datetime(1995, 10, 10, 0, 0),
datetime.datetime(1996, 10, 10, 0, 0),
datetime.datetime(1997, 10, 10, 0, 0),
datetime.datetime(1998, 10, 10, 0, 0),
datetime.datetime(1999, 10, 10, 0, 0),
datetime.datetime(2000, 10, 9, 0, 0),
datetime.datetime(2001, 10, 8, 0, 0),
datetime.datetime(2002, 10, 14, 0, 0),
datetime.datetime(2003, 10, 13, 0, 0),
datetime.datetime(2004, 10, 11, 0, 0),
datetime.datetime(2005, 10, 10, 0, 0),
datetime.datetime(2006, 10, 9, 0, 0),
datetime.datetime(2007, 10, 8, 0, 0),
datetime.datetime(2008, 10, 13, 0, 0),
datetime.datetime(2009, 10, 12, 0, 0),
datetime.datetime(2010, 10, 11, 0, 0),
datetime.datetime(2011, 10, 10, 0, 0),
datetime.datetime(2012, 10, 8, 0, 0),
datetime.datetime(2013, 10, 14, 0, 0),
datetime.datetime(2014, 10, 13, 0, 0),
datetime.datetime(2015, 10, 12, 0, 0),
datetime.datetime(2016, 10, 10, 0, 0),
datetime.datetime(2017, 10, 9, 0, 0)]
これで体育の日の日付情報の準備ができました。
1都市に対するデータ処理
まずは1つの都市に対してデータ処理を行い、どういった作業をしていくかの方針を決めます。
初めにライブラリのimportと基本的な設定をいくつか行なっておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
plt.rcParams["font.size"] = 12
root_dir = "../input/weather_of_sports_day/"
次にデータを取り込みます。先ほど確認したファイルの中身を踏まえ、不要な部分をskipしておきます。
tokyo_df = pd.read_csv(os.path.join(root_dir, "tokyo.csv"), skiprows=[0, 1, 2, 4, 5], encoding="cp932")
tokyo_df.head()
| 年月日 | 平均気温(℃) | 最高気温(℃) | 最低気温(℃) | 日照時間(時間) | 日照時間(時間).1 | 平均風速(m/s) | 最小相対湿度(%) | 平均湿度(%) | 平均蒸気圧(hPa) | 天気概況(昼:06時~18時) | 平均雲量(10分比) | 天気概況(夜:18時~翌日06時) | 降水量の合計(mm) | 降水量の合計(mm).1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1989/10/1 | NaN | NaN | NaN | NaN | NaN | NaN | 45 | NaN | NaN | 晴後曇 | 7.8 | 曇一時雨 | 0.0 | 1 |
| 1 | 1989/10/2 | NaN | NaN | NaN | NaN | NaN | NaN | 58 | NaN | NaN | 曇時々雨 | 10.0 | 曇 | 0.0 | 0 |
| 2 | 1989/10/3 | NaN | NaN | NaN | NaN | NaN | NaN | 62 | NaN | NaN | 曇後雨 | 10.0 | 雨一時曇 | 0.0 | 0 |
| 3 | 1989/10/4 | NaN | NaN | NaN | NaN | NaN | NaN | 67 | NaN | NaN | 雨後曇 | 10.0 | 曇後晴 | 34.0 | 0 |
| 4 | 1989/10/5 | NaN | NaN | NaN | NaN | NaN | NaN | 53 | NaN | NaN | 晴 | 3.5 | 晴後曇一時雨 | 0.0 | 1 |
この時点で列情報を限定してもよかったのですが、今回はあとで絞る方式にしました。
次は列名をアルファベット表記に変えます。一旦リストを作ったあと、変更用のdictを作成します。
rename_cols = ["date", "temp_mean", "temp_max", "temp_min", "day_length", "day_length_existence", "wind_strength",
"humidity_min", "humidity_mean", "vp_mean", "weather_day", "clouds_mean", "weather_night", "rain_amount", "rain_existence"]
rename_dict = {base_col: new_col for base_col, new_col in zip(tokyo_df.columns, rename_cols)}
これで、元のデータフレームに対応する辞書ができました。例えば{“年月日”: “date”}のように、{元の列名: 新しい列名}になっています。
あと、ここで使用する列名(変更後)のリストも作成しておきます。
use_cols = ["date", "rain_amount", "rain_existence"]
これらを使ってrenameと列情報の限定をします。
tokyo_df = tokyo_df.rename(columns=rename_dict)
tokyo_df = tokyo_df[use_cols]
tokyo_df.head()
| date | rain_amount | rain_existence | |
|---|---|---|---|
| 0 | 1989/10/1 | 0.0 | 1 |
| 1 | 1989/10/2 | 0.0 | 0 |
| 2 | 1989/10/3 | 0.0 | 0 |
| 3 | 1989/10/4 | 34.0 | 0 |
| 4 | 1989/10/5 | 0.0 | 1 |
これで必要な情報を絞れました。次に、グラフのラベルに使用するための年度ごとの情報をデータフレームに持たせます。
関数を準備して、pandas.Series.apply()を使用して、年月日の要素から年をとってくる方式にしました。
事前に、年月日の列を文字列からdatetime型に変換しています。
def return_year(cdatetime):
return str(cdatetime.year)
tokyo_df["date"] = pd.to_datetime(tokyo_df["date"])
tokyo_df["year"] = tokyo_df["date"].apply(return_year)
最後に、体育の日の情報だけを抽出します。事前に体育の日のリストは作っていたので、isin()を使用すればOKです。
tokyo_df_main = tokyo_df[tokyo_df["date"].isin(sports_day_list)]
tokyo_df_main
| date | rain_amount | rain_existence | year | |
|---|---|---|---|---|
| 9 | 1989-10-10 | 0.0 | 1 | 1989 |
| 30 | 1990-10-10 | 0.0 | 1 | 1990 |
| 51 | 1991-10-10 | 11.5 | 0 | 1991 |
| 72 | 1992-10-10 | 0.0 | 1 | 1992 |
| 93 | 1993-10-10 | 0.0 | 1 | 1993 |
tokyo_df_main
| date | rain_amount | rain_existence | year | |
|---|---|---|---|---|
| 9 | 1989-10-10 | 0.0 | 1 | 1989 |
| 30 | 1990-10-10 | 0.0 | 1 | 1990 |
| 51 | 1991-10-10 | 11.5 | 0 | 1991 |
| 72 | 1992-10-10 | 0.0 | 1 | 1992 |
| 93 | 1993-10-10 | 0.0 | 1 | 1993 |
| 114 | 1994-10-10 | 0.0 | 0 | 1994 |
| 135 | 1995-10-10 | 0.0 | 1 | 1995 |
| 156 | 1996-10-10 | 0.0 | 1 | 1996 |
| 177 | 1997-10-10 | 0.0 | 0 | 1997 |
| 198 | 1998-10-10 | 0.0 | 0 | 1998 |
| 219 | 1999-10-10 | 0.0 | 1 | 1999 |
| 239 | 2000-10-09 | 19.5 | 0 | 2000 |
| 259 | 2001-10-08 | 11.5 | 0 | 2001 |
| 286 | 2002-10-14 | 0.0 | 1 | 2002 |
| 306 | 2003-10-13 | 60.0 | 0 | 2003 |
| 325 | 2004-10-11 | 3.5 | 0 | 2004 |
| 345 | 2005-10-10 | 18.5 | 0 | 2005 |
| 365 | 2006-10-09 | 0.0 | 1 | 2006 |
| 385 | 2007-10-08 | 4.0 | 0 | 2007 |
| 411 | 2008-10-13 | 0.0 | 1 | 2008 |
| 431 | 2009-10-12 | 0.0 | 1 | 2009 |
| 451 | 2010-10-11 | 0.0 | 1 | 2010 |
| 471 | 2011-10-10 | 6.0 | 0 | 2011 |
| 490 | 2012-10-08 | 0.0 | 1 | 2012 |
| 517 | 2013-10-14 | 0.0 | 0 | 2013 |
| 537 | 2014-10-13 | 49.0 | 0 | 2014 |
| 557 | 2015-10-12 | 0.0 | 1 | 2015 |
| 576 | 2016-10-10 | 0.0 | 0 | 2016 |
| 596 | 2017-10-09 | 0.0 | 0 | 2017 |
データフレームが準備できたので、描画も試しておきます。
fig, ax = plt.subplots(figsize=(8, 3))
main_df = tokyo_df_main
data_points = np.arange(len(main_df))
ax.bar(data_points,main_df["rain_amount"])
ax.set_xticks(data_points)
ax.set_xticklabels(main_df["year"], rotation=50, fontsize=10)
ax.set_xlim([-1, 29])
ax.set_title("Tokyo",fontsize=14)
ax.set(xlabel="year", ylabel="rain_amount")
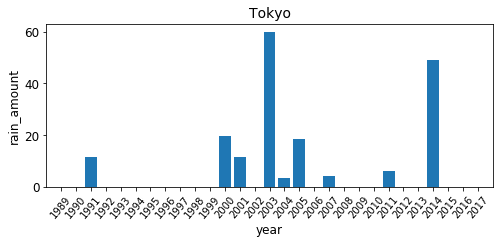
これで1つの都市に対するグラフが作成できました。
工夫としては、横軸をこちらで指定したことぐらいなのですが、実は特に必要ありません。
axes.bar()の第一引数にtarget_df[“year”]を指定してあげれば問題ありません。その場合軸が少しずれますが、そこは調整すれば大丈夫です。
とはいえ、今回はこのコードで実施したので、このまま話を続けていきます。
「現象なし情報」を使用するかの判断
次に、冒頭で少し触れた「現象なし情報」についての判断を行いました。
これは、「降雨」という現象があったかどうかを示すフラグのようでした。データを見る限り、1なら「現象なし」、0なら「現象あり」のようです。
0mmの降雨量でも「現象あり」になっているデータがあったのは、0~0.9mmの雨は0mm扱い、というところにありそうです。
なので、この「現象なし」情報が使えれば、少し話が楽になりそうですね。では、これが0か1かで単純に棒グラフを作成してみましょう。
fig, ax = plt.subplots(figsize=(8, 3))
main_df = tokyo_df_main
data_points = np.arange(len(main_df))
ax.bar(data_points,main_df["rain_existence"])
ax.set_xticks(data_points)
ax.set_xticklabels(main_df["year"], rotation=50, fontsize=10)
ax.set_xlim([-1, 29])
ax.set_title("Tokyo",fontsize=14)
ax.set(xlabel="year", ylabel="rain_amount")
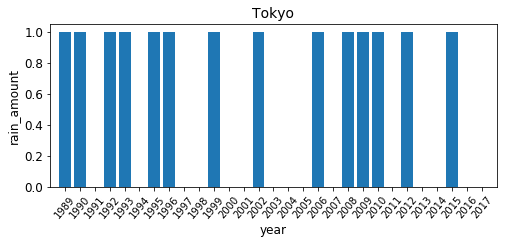
現象なし情報が1になった、つまり、雨が一切降っていないとされるデータは14個でした。全29データのうちのおよそ半分です。
存外2年に1回は雨が降っている、ということになりますね。
少し悩みましたが、今回は、「雨が降っている印象」に対する調査ということで、0mm扱いにされるような雨はカウントしない方向にしました。
恣意的にデータを扱っているようになりますが、本分析における前提として提示しているので、分析の方針としては間違っていない…と信じたいです。
3都市に対するデータ処理
ここまでで一つの都市に対しての前処理と作図の方法を確認しました。また、「現象なし」情報は使わないことに決めました。
これを踏まえて、まとめてデータを処理するコードを書いていきます。
ここでは3都市に対するグラフの作成を行いますが、前処理の流れは共通なので、先にすべての都市の情報をもつデータフレームを作成します。
まずは事前にちょっとした準備です。
city_list= ["Sapporo", "Tokyo", "Yokohama", "Nagoya", "Osaka", "Fukuoka"]
use_cols = ["date", "rain_amount"]
次に、前処理を行う関数を作成しておきます。
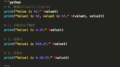
def preprocess_func(city_name, rename_dict, use_cols):
filepath = os.path.join(root_dir, city_name.lower() + ".csv")
base_df = pd.read_csv(filepath, skiprows = [0,1,2,4,5], encoding="cp932")
renamed_df = base_df.rename(columns=rename_dict)
main_df = renamed_df[use_cols]
main_df["date"] = pd.to_datetime(main_df["date"])
return main_df
初めの10行ほど確認しておきましょう。
main_df.head(10)
| date | Sapporo | Tokyo | Yokohama | Nagoya | Osaka | Fukuoka | |
|---|---|---|---|---|---|---|---|
| 0 | 1989-10-01 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 1989-10-02 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 1989-10-03 | 0.0 | 0.0 | 3.5 | 1.0 | 6.5 | 0.0 |
| 3 | 1989-10-04 | 0.0 | 34.0 | 37.0 | 0.0 | 0.0 | 0.0 |
| 4 | 1989-10-05 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5 | 1989-10-06 | 1.5 | 5.0 | 4.5 | 0.0 | 0.0 | 0.0 |
| 6 | 1989-10-07 | 0.0 | 13.0 | 9.0 | 9.5 | 0.0 | 0.0 |
| 7 | 1989-10-08 | 1.0 | 0.5 | 1.0 | 0.0 | 0.5 | 1.5 |
| 8 | 1989-10-09 | 1.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 9 | 1989-10-10 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 2.0 |
あとは、年の情報、体育の日かどうかの情報を追加しておきます。
main_df["year"] = main_df["date"].apply(return_year)
main_df["is_sports_day"] = main_df["date"].isin(sports_day_list).apply(int)
体育の日の抽出結果がこちらです。
main_df[main_df["is_sports_day"] == 1 ]
| date | Sapporo | Tokyo | Yokohama | Nagoya | Osaka | Fukuoka | year | is_sports_day | |
|---|---|---|---|---|---|---|---|---|---|
| 9 | 1989-10-10 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 2.0 | 1989 | 1 |
| 30 | 1990-10-10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1990 | 1 |
| 51 | 1991-10-10 | 0.0 | 11.5 | 19.5 | 2.0 | 8.5 | 0.0 | 1991 | 1 |
| 72 | 1992-10-10 | 20.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1992 | 1 |
| 93 | 1993-10-10 | 5.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1993 | 1 |
| 114 | 1994-10-10 | 0.0 | 0.0 | 0.0 | 1.0 | 1.5 | 0.0 | 1994 | 1 |
| 135 | 1995-10-10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1995 | 1 |
| 156 | 1996-10-10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1996 | 1 |
| 177 | 1997-10-10 | 4.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1997 | 1 |
| 198 | 1998-10-10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1998 | 1 |
| 219 | 1999-10-10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1999 | 1 |
| 239 | 2000-10-09 | 0.0 | 19.5 | 24.0 | 7.0 | 45.5 | 11.5 | 2000 | 1 |
| 259 | 2001-10-08 | 0.0 | 11.5 | 9.0 | 0.0 | 0.0 | 0.5 | 2001 | 1 |
| 286 | 2002-10-14 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2002 | 1 |
| 306 | 2003-10-13 | 1.5 | 60.0 | 29.5 | 41.0 | 34.0 | 7.0 | 2003 | 1 |
| 325 | 2004-10-11 | 11.0 | 3.5 | 5.5 | 0.0 | 0.0 | 0.0 | 2004 | 1 |
| 345 | 2005-10-10 | 0.5 | 18.5 | 19.0 | 2.0 | 7.0 | 0.0 | 2005 | 1 |
| 365 | 2006-10-09 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2006 | 1 |
| 385 | 2007-10-08 | 7.0 | 4.0 | 1.0 | 8.5 | 4.5 | 37.5 | 2007 | 1 |
| 411 | 2008-10-13 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2008 | 1 |
| 431 | 2009-10-12 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2009 | 1 |
| 451 | 2010-10-11 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2010 | 1 |
| 471 | 2011-10-10 | 9.5 | 6.0 | 8.5 | 0.0 | 0.0 | 0.0 | 2011 | 1 |
| 490 | 2012-10-08 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2012 | 1 |
| 517 | 2013-10-14 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2013 | 1 |
| 537 | 2014-10-13 | 0.0 | 49.0 | 46.0 | 60.0 | 71.0 | 105.0 | 2014 | 1 |
| 557 | 2015-10-12 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.5 | 2015 | 1 |
| 576 | 2016-10-10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2016 | 1 |
| 596 | 2017-10-09 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2017 | 1 |
見たところきちんと抽出できていそうです。
このデータフレームをsports_day_dfすることにします。
sports_day_df = main_df[main_df["is_sports_day"] == 1 ]
3都市に対するプロット
準備ができたのでまずは東京、名古屋、大阪の3都市に対するプロットを作成します。
まずはシンプルなプロット結果です。
# 3都市での雨量のプロット
three_cities = ["Tokyo", "Nagoya", "Osaka"]
fig, axes = plt.subplots(nrows=3, ncols=1, figsize=(8, 9), sharey = False)
target_df = sports_day_df
for city, ax in zip(three_cities, axes.flatten()):
data_points = np.arange(len(target_df))
ax.bar(data_points,target_df[city])
ax.set_xticks(data_points)
ax.set_xticklabels(target_df["year"], rotation=50, fontsize=10)
ax.set_xlim([-1, 29])
ax.set_title(city,fontsize=14)
ax.set(xlabel="year", ylabel="rain_amount")
plt.subplots_adjust(hspace=0.7)
sharey = Falseにしましたが、元々これらの3都市の最大雨量が近かったおかげで縦軸が揃っていますね。
このグラフに対する考察は、検証の方で記載した通りなのでここでは省きます。
6都市に対するデータ処理
あとは同じことの繰り返しです。
まずシンプルにグラフを作成します。
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(16, 9), sharey = False)
target_df = sports_day_df
for city, ax in zip(city_list, axes.flatten()):
data_points = np.arange(len(target_df))
ax.bar(data_points,target_df[city])
ax.set_xticks(data_points)
ax.set_xticklabels(target_df["year"], rotation=50, fontsize=10)
ax.set_xlim([-1, 29])
ax.set_title(city,fontsize=14)
ax.set(xlabel="year", ylabel="rain_amount")
plt.subplots_adjust(hspace=0.7)
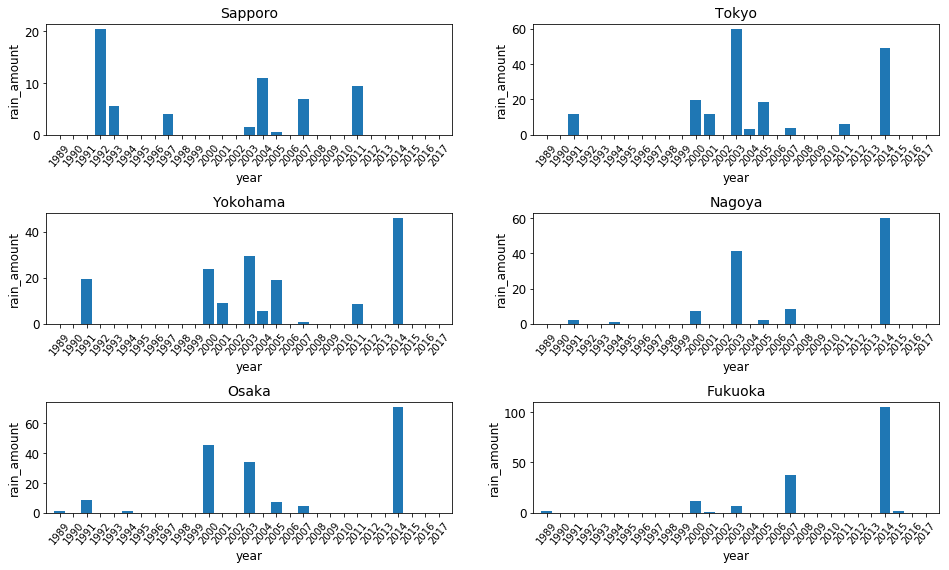
これは、今回考察の方では採用しなかったグラフです。その理由は、グラフが描画される順番です。
左上段、右上段、左中段、右中段…という順番で描画されています。
別にこれでも構わないのですが、今回自分でグラフを眺めていて、グラフを比較するときは主に同じ年度を見ていることに気づいたことが、このグラフを採用しなかった理由です。
天気は地理的に近い方が似ていると考え、比較の際になるべくグラデーションになっているようにした方が好ましいと考えました。
そこで、下記のようなコードにすることで、グラフの描画順序を変更しました。
# 見辛いので北側から左に並べなおす
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(16, 9), sharey = False)
target_df = sports_day_df
for i, city in enumerate(city_list):
ax = axes[i % 3, i//3]
data_points = np.arange(len(target_df))
ax.bar(data_points,target_df[city])
ax.set_xticks(data_points)
ax.set_xticklabels(target_df["year"], rotation=50, fontsize=10)
ax.set_xlim([-1, 29])
ax.set_title(city,fontsize=14)
ax.set(xlabel="year", ylabel="rain_amount")
plt.subplots_adjust(hspace=0.6)
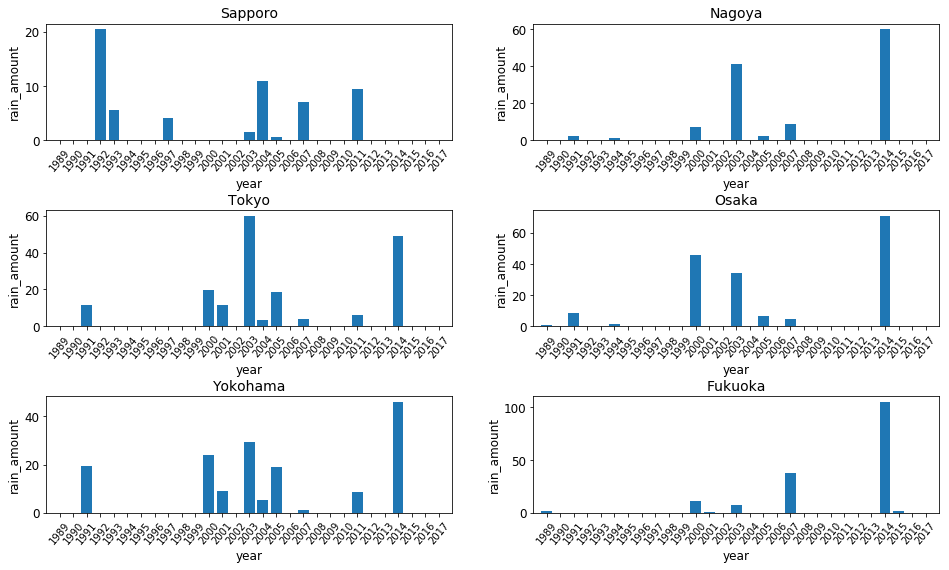
これでグラフは縦に比較しやすくなっています。最後に、sharey=Trueを入れて、縦軸が共通になっているグラフを作成します。
# sharey = Trueを入れる
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(16, 9), sharey = True)
target_df = sports_day_df
for i, city in enumerate(city_list):
ax = axes[i % 3, i//3]
data_points = np.arange(len(target_df))
ax.bar(data_points,target_df[city])
ax.set_xticks(data_points)
ax.set_xticklabels(target_df["year"], rotation=50, fontsize=10)
ax.set_xlim([-1, 29])
ax.set_title(city,fontsize=14)
ax.set(xlabel="year", ylabel="rain_amount")
plt.subplots_adjust(hspace=0.7)
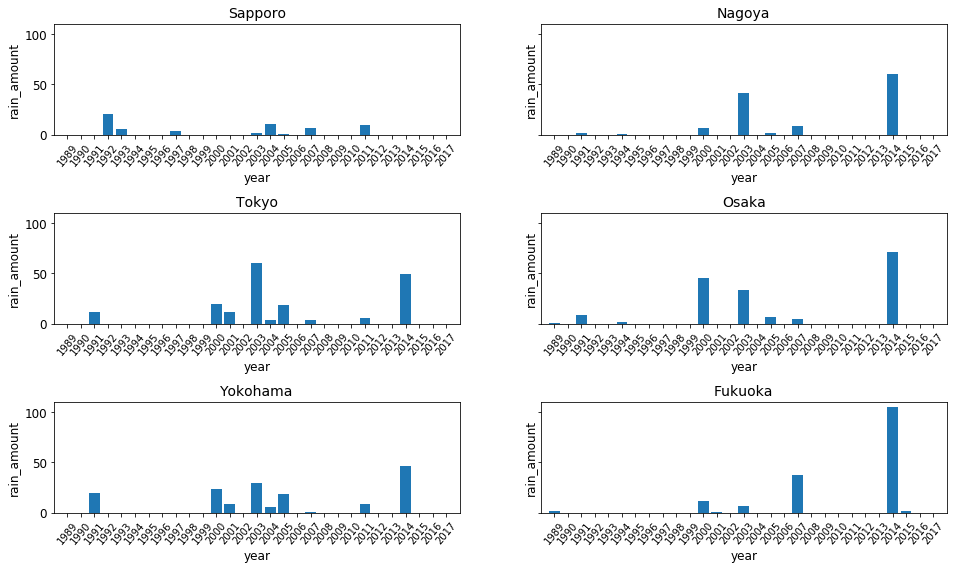
これで降雨量の絶対値の比較ができるようになりました。
1mm以上の雨が降った回数のカウント
続いて、体育の日は他の日よりも雨が降っていないかどうか検証するため、日毎の雨の有無を集計していきます。
この際、条件として、「体育の日」を基準とした差の日数の情報が必要でした。
また、この後で「特異日である10月14日は他の日より雨が少ないか」ということも検証します。
それらを踏まえて、データフレームに情報を足していきます。
まずは、便利な関数を準備しました。
def return_date(each_datetime):
return each_datetime.strftime("%m/%d")
def return_diff_from_sportday(each_datetime, sports_day_dict):
focus_year = return_year(each_datetime)
sports_day_for_the_year = sports_day_dict[focus_year]
date_diff = each_datetime - sports_day_for_the_year
return date_diff.days
def add_israin(c_df, city):
c_series = c_df[city] > 0
c_series = c_series.apply(int)
c_df["is_rain_"+city] = c_series
return c_df
また、これも後で使うために、年度ごとに体育の日を返す辞書を用意しておきます。
sports_day_dict = {return_year(each) : each for each in sports_day_list}
一旦下準備はこれで完了です。
体育の日とその他の日の雨の頻度の検証
それでは、用意した関数を使って情報を追加していきます。
main_df["diff_from_sportsday"] = main_df["date"].apply(return_diff_from_sportday, args=(sports_day_dict,))
for city in city_list:
main_df = add_israin(main_df, city)
体育の日から何日の位置の情報かと、1mm以上の雨が降ったかどうかの情報を追加しました。
これを使って、各都市で体育の日に何回雨が降ったかも確認して見ましょう。
israin_colname_list = ["is_rain_"+city for city in city_list]
main_df[main_df.date.isin(sports_day_list)][israin_colname_list].sum(axis=0).reset_index().rename(columns={0:"counts"})
| index | counts | |
|---|---|---|
| 0 | is_rain_Sapporo | 8 |
| 1 | is_rain_Tokyo | 9 |
| 2 | is_rain_Yokohama | 9 |
| 3 | is_rain_Nagoya | 7 |
| 4 | is_rain_Osaka | 8 |
| 5 | is_rain_Fukuoka | 7 |
この表を使うと、雨が降った頻度だけを知りたい場合、グラフを使うより分かりやすいですね。
話が逸れましたが本題に戻ります。雨が降った頻度を数えるにはgroupbyとsumを利用します。
今回は体育の日±7日のデータだけに注目します。
diff_from_sports_day_sum = main_df.groupby(by="diff_from_sportsday").sum()
count_df_for_sports_day_diff = diff_from_sports_day_sum[(diff_from_sports_day_sum.index <= 7) & (diff_from_sports_day_sum.index >= -7)]
そして、これを描画すると下記のようになります。
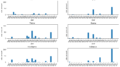
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(16, 9), sharey = True)
target_df = count_df_for_sports_day_diff
for i,city in enumerate(city_list):
count_col = "is_rain_" + city
ax = axes[i % 3, i//3]
data_points = np.arange(-7,8)
ax.bar(data_points,target_df[count_col])
ax.set_xticks(data_points)
ax.set_xticklabels(target_df.index, rotation=0, fontsize=9)
ax.set_xlim([-8, 8])
ax.set_title(city,fontsize=14)
ax.set(xlabel="day_difference", ylabel="counts")
plt.subplots_adjust(hspace=0.7)
plt.show()
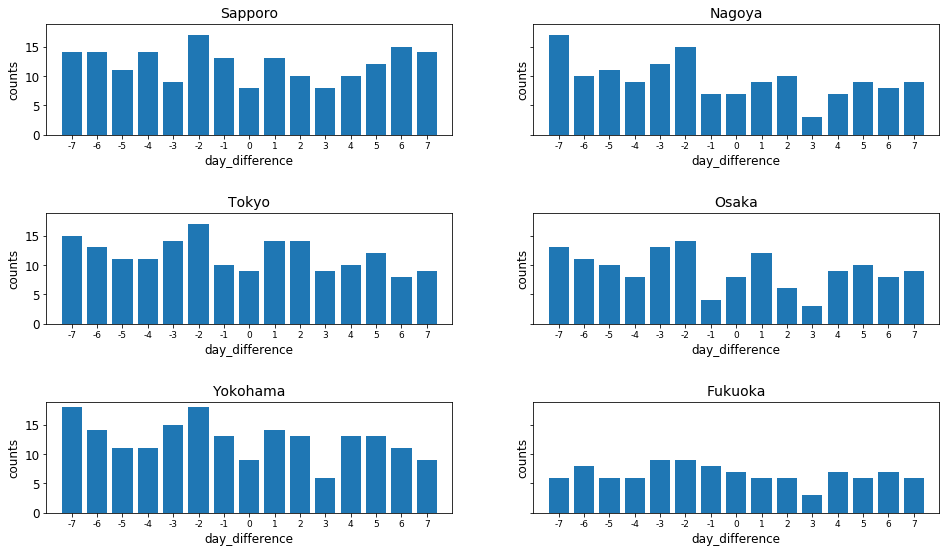
やっていること自体は非常に単純です。
特異日とされる10月14日は他の日よりも雨が少ないかどうかの検証
最後に、10月14日は雨が少ないかどうかの検証です。
まずはデータフレームに月と日からなる情報を追加します。これを追加する理由は、後でgroupbyを使用するためです。
main_df["month_day"] = main_df["date"].apply(return_date)
準備ができたのでgroupbyを取ります。
sum_by_day_df = main_df.groupby(by="month_day").sum()
sum_by_day_df.head()
| Sapporo | Tokyo | Yokohama | Nagoya | Osaka | Fukuoka | is_sports_day | diff_from_sportsday | is_rain_Sapporo | is_rain_Tokyo | is_rain_Yokohama | is_rain_Nagoya | is_rain_Osaka | is_rain_Fukuoka | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| month_day | ||||||||||||||
| 10/01 | 122.0 | 329.0 | 401.0 | 322.5 | 238.0 | 122.5 | 0 | -275 | 12 | 18 | 18 | 13 | 12 | 8 |
| 10/02 | 143.0 | 176.5 | 183.0 | 108.0 | 94.5 | 227.5 | 0 | -246 | 14 | 11 | 11 | 10 | 10 | 12 |
| 10/03 | 106.0 | 116.0 | 140.5 | 66.5 | 72.5 | 35.0 | 0 | -217 | 13 | 10 | 10 | 12 | 8 | 7 |
| 10/04 | 147.0 | 126.5 | 101.0 | 67.5 | 100.5 | 30.5 | 0 | -188 | 13 | 10 | 12 | 9 | 7 | 5 |
| 10/05 | 73.0 | 399.0 | 426.5 | 176.5 | 96.0 | 86.5 | 0 | -159 | 14 | 13 | 14 | 12 | 13 | 9 |
描画は特異日の±7日に絞りたいので、抽出用のリストを作成します。
days_list_for_specific_day = ["10/" + str(num).zfill(2) for num in range(7, 22)]
最後に、このリストを使ってデータを抽出すればデータの準備は完了です。
days_df_for_specific_day = sum_by_day_df[sum_by_day_df.index.isin(days_list_for_specific_day)]
このデータを使って、特異日を中心に前後7日間の都市ごとのデータをプロットしましょう。
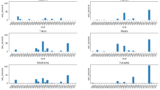
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(16, 9), sharey = True)
for i,city in enumerate(city_list):
count_col = "is_rain_" + city
ax = axes[i % 3, i//3]
data_points = np.arange(-7,8)
ax.bar(data_points,days_df_for_specific_day[count_col])
ax.set_xticks(data_points)
ax.set_xticklabels(days_df_for_specific_day.index, rotation=50, fontsize=10)
ax.set_xlim([-8, 8])
ax.set_title(city,fontsize=14)
ax.set(xlabel="date", ylabel="counts")
plt.subplots_adjust(hspace=0.7)
plt.show()
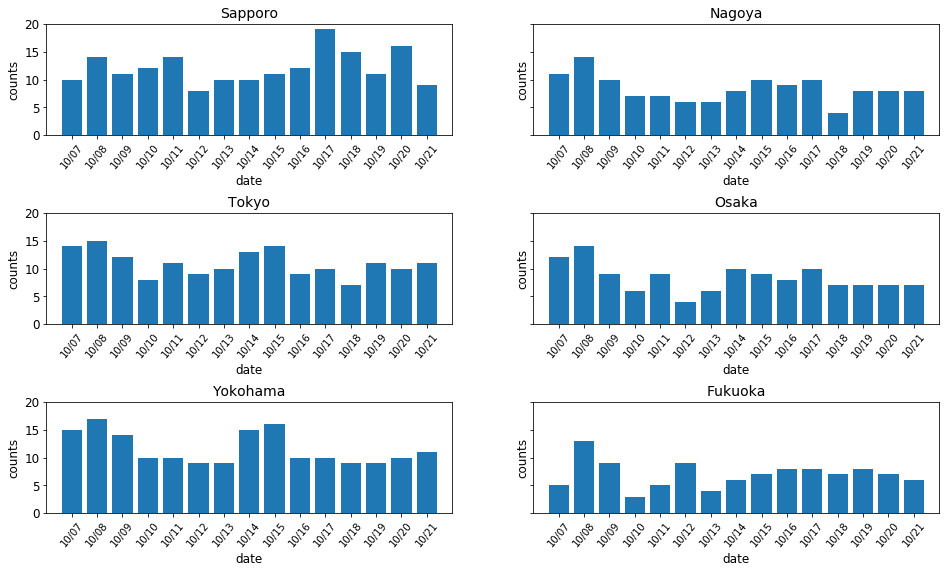
以上で、検証に使用したコードの紹介は終わりです。
まとめ
非常に長くなってしまいましたが、体育の日の天気に関する検証を行なった際に使用したコードを紹介しました。
レベルとしては本当にPythonとPandasの基本を勉強して、実際に使ってみたいというぐらいだと思います。
色々やっていますが、分からないことがあったら都度都度調べてなんとかかんとかやっている状態です。
まだまだ上のレベルがあると思うので、楽しみながら少しずつ勉強していきたいと思います。
作成したグラフを使っての検証編も再掲しておきます。
結局、多くの人にとって必要なのは「得られたデータから何が言えるか」、というところなので、人に伝える部分では必要なことを適切に、ということが重要になってくるのだろうなぁと改めて感じました。
学ぶことはまだまだ多そうです。
参考資料
気象庁ホームページ-データ取得画面 https://www.data.jma.go.jp/gmd/risk/obsdl/index.php