今回はDataFrame.to_excle()でデータフレームを異なるシートに追記で出力していく方法を整理します。
実用的に必要な場面はあるのですが、よく調べるのでまとめておきたいというのがモチベーションです。
紹介している方法が上手く使えない時は、Pandasのバージョンやopenpyxlなどの有無を確認してみてください。
主な参考資料
今回の主な参考資料はこちらです。
– https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html
– https://stackoverflow.com/questions/20219254/how-to-write-to-an-existing-excel-file-without-overwriting-data-using-pandas
– https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.ExcelWriter.html#pandas.ExcelWriter
技術の解説
to_excelの基本
まず前提としてDataFrame.to_excel()の基本を紹介します。
to_excel()を使うときは、pandas.ExcelWriter()を使う必要があります。
サンプルを見てみましょう。こちらは追記モードではなく、シンプルに書き出しているだけです。
import numpy as np
import pandas as pd
import os
import datetime
# savenameは例えば"../output/sample.xlsx"のような、エクセルの出力に対応した名称
cdf = pd.DataFrame({"C1": [4,3,2,1], "C2": [8, 7, 6, 5]})
with pd.ExcelWriter(savename, engine="openpyxl") as writer:
cdf.to_excel(writer, sheet_name="sample_sheet", index=False)
主な流れは、出力したいDataFrame, writer, シート名の指定です。
ExcelWriterの引数engineでは、openpyxlかxlsxwriterのどちらかを指定します。
これは処理に利用するモジュールを指定していることに当たるかと思います。
パフォーマンスに違いが出てくるようなので、しっかり調べたいところですが、ここではフォーカス外とします。
追記モード
次に、追記の方法です。やることは非常にシンプルで、mode=”a”を入れてあげるだけです。
# savenameは例えば"../output/sample.xlsx"のような、エクセルの出力に対応した名称
with pd.ExcelWriter(savename, engine="openpyxl", mode="a") as writer:
cdf.to_excel(writer, sheet_name=sheetname, index=False)
但し、savenameで指定したパスがない場合はエラーを吐くので、os.path.exists()などで存在確認を入れてあげると良いかと思います。存在確認も含めたコードを次の実用例で紹介します。
上手く動かない時
動くはずのコードが上手く動いてくれない場合があります。
今回筆者も遭遇したのですが、その時は環境の違いが原因でした。
バージョンの違い(今回はPandas0.24.2を使用)、モジュールの不足(openpyxlやxlsxwriterの有無)などに注意して、必要であれば新たにpip installするなどしてご対応ください。
実用例
今回は、シート名を変えながらファイルに追記していきます。
そのため、先に一つだけ、出力用のデータフレームを作成する関数を準備しておきます。
事前準備
def create_sample_df(start_datetime, data_length=100):
cdf = pd.DataFrame(data={"datetime":[start_datetime + datetime.timedelta(minutes=i) for i in range(data_length)],
"value": np.random.normal(0, 1,data_length)},columns=["datetime", "value"])
return cdf
サンプルはこんな感じです。
sample_df = create_sample_df(datetime.datetime(2019, 7,10))
sample_df.head()
こちらはただのダミーの出力なので特に重要ではありません。
本題
今回の本題です。この例では、”./output/sample.xlsx”というファイルに3月1日から1日ごとのデータをシート名を日付にしながら出力していきます。
このコードではすでに”./output/sample.xlxs”が存在していた場合は削除するようにしています。
savename = os.path.join("./output/", "sample.xlsx")
start_datetime = datetime.datetime(2019, 3,1)
if os.path.exists(savename):
os.remove(savename)
for i in range(10):
c_start_datetime = start_datetime + datetime.timedelta(days=i)
sheetname = start_datetime.strftime("%y%m%d")
cdf = create_sample_df(start_datetime)
if os.path.exists(savename):
with pd.ExcelWriter(savename, engine="openpyxl", mode="a") as writer:
cdf.to_excel(writer, sheet_name=sheetname, index=False)
else:
with pd.ExcelWriter(savename, engine="openpyxl") as writer:
cdf.to_excel(writer, sheet_name=sheetname, index=False)
出力結果を見てみましょう。エクセルファイルをGoogleドライブにアップロードしたプレビューを示します。
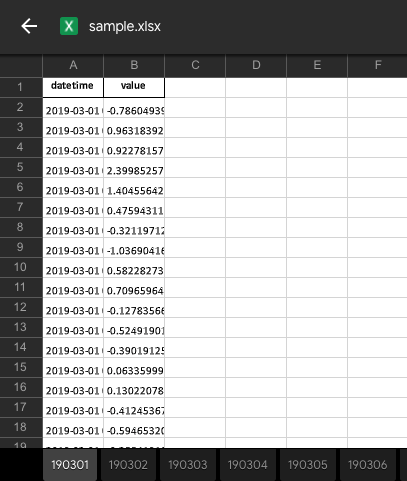
編集の都合途中で切ってしまっていますが、データ自体は一応期待通りです。
が、幅の調整がいまいちです。
はじめに出てきたExcelWriter()の引数”engine”で指定するopenpyxlなどを上手く活用することで、この幅の調整なども含めたコードを作成することができます。
こちらはまた後日整理させてもらえればと思います。
関数化した例
上の出力だと再利用が面倒なので、関数化した例を示します。
def write_excel_file_test(start_datetime, savename):
dirpath = "{}".format(os.sep).join(savename.split(os.sep)[:-1])
if not os.path.exists(dirpath):
os.makedirs(dirpath)
if os.path.exists(savename):
os.remove(savename)
for i in range(10):
c_start_datetime = start_datetime + datetime.timedelta(days=i)
sheetname = c_start_datetime.strftime("%y%m%d")
cdf = create_sample_df(c_start_datetime)
if os.path.exists(savename):
with pd.ExcelWriter(savename, engine="openpyxl", mode="a") as writer:
cdf.to_excel(writer, sheet_name=sheetname, index=False)
else:
with pd.ExcelWriter(savename, engine="openpyxl") as writer:
cdf.to_excel(writer, sheet_name=sheetname, index=False)
return cdf
使用例はこちら。
start_datetime = datetime.datetime(2019, 4, 1)
savename = os.path.join("./output/", "sample2.xlsx")
_ = write_excel_file_test(start_datetime, savename)
返り値にデータフレームを指定していますが、特に使う予定はないので出力先にアンダースコアを使っています。
出力結果のスクリーンショットは以下の通り。

基本的には先ほどと同じです。
以上、特に意味はないのですが、関数化してみた結果でした。
まとめ
to_excle()を使って複数のデータフレームを異なるシートに追記する形で出力していく方法を整理しました。
何度も調べるのが面倒だったのをまとめただけなので、お役に立てば幸いです。
また折を見て出力形式も整えた形の関数をコピペ用に準備したいと思います。
重ねてになってしまいますが、紹介している方法が上手く使えない時は、Pandasのバージョンやopenpyxlなどの有無を確認してみてください。
それでは。
参考資料
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_excel.html
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.ExcelWriter.html#pandas.ExcelWriter
- https://stackoverflow.com/questions/20219254/how-to-write-to-an-existing-excel-file-without-overwriting-data-using-pandas
- https://openpyxl.readthedocs.io/en/stable/tutorial.html
- https://github.com/pandas-dev/pandas/issues/4542
- https://stackoverflow.com/questions/6996603/delete-a-file-or-folder